| 6. C-JDBC controller | ||
|---|---|---|
 |  | |
| 6. C-JDBC controller | ||
|---|---|---|
| | | |
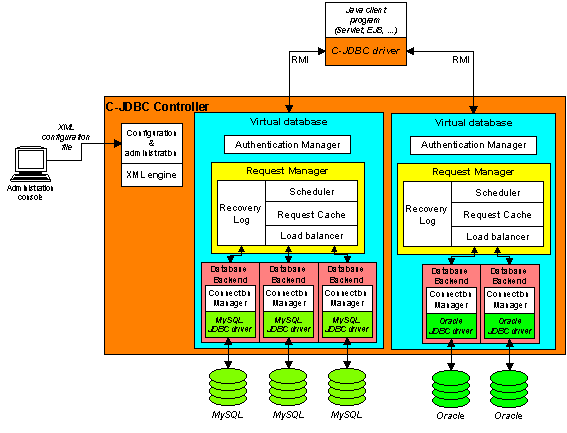
The C-JDBC controller is made of several components as shown in Figure 2, “C-JDBC controller design overview”. The controller hosts virtual databases. A virtual database gives the illusion of a single database to the user. It exports the same database name and login/password as those used in the client application. Therefore the client application can run unmodified with C-JDBC.
When the client application connects to the database using an URL like jdbc:cjdbc://host:25322/myDB, the C-JDBC driver tries to connect to a C-JDBC controller running on port 25322 on node host. Once the connection is established the login and password are sent with the myDB database name to be checked by the controller.
A virtual database contains the following components:
authentication manager: it matches the virtual database login/password (provided by the application to the C-JDBC driver) with the real login/password to use on each backend. The authentication manager is only involved at connection establishment time.
backup manager: manages a list of generic or database specific Backupers that are in charge of performing database dump and restore operation. Backupers should also take careof transferring dumps from one controller to another.
request manager: it handles the requests coming from a connection with a C-JDBC driver. It is composed of several components:
scheduler: it is responsible for scheduling the requests. Each RAIDb level has its own scheduler.
request caches: these are optional components that can cache query parsing, the result set and result metadata of queries.
load balancer: it balances the load on the underlying backends according to the chosen RAIDb level configuration.
recovery log: it handles checkpoints and allows backends to dynamically recover from a failure or to be dynamically added to a running cluster.
database backend: it represents the real database backend running the RDBMS engine. A connection manager mainly provides connection pooling on top of the database JDBC native driver.
Each virtual database and its components are configured using an XML configuration file that is sent from the administration console to the C-JDBC controller.
![[Note]](../../images/note.gif) | Note |
|---|---|
A research report details RAIDb and C-JDBC implementation. Other documents and presentations about C-JDBC can be found in the documentation section of the web site. | |
The bin directory of the C-JDBC distribution contains the scripts to start the controller. Unix users must start the controller with controller.sh whereas Windows users will use controller.bat.
Since C-JDBC Controller version 1.0b11, the controller start is tuned via a configuration file, called controller.xml, included under the config/controller directory of your C-JDBC installation. A simple configuration file looks like this:
A standard C-JDBC Controller configuration file looks like this:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE C-JDBC-CONTROLLER PUBLIC "-//ObjectWeb//DTD C-JDBC-CONTROLLER 2.0.2//EN" "http://c-jdbc.objectweb.org/dtds/c-jdbc-controller-2.0.2.dtd">
<C-JDBC-CONTROLLER>
<Controller port="25322">
<Report hideSensitiveData="true" generateOnFatal="true"/>
<JmxSettings>
<RmiJmxAdaptor/>
</JmxSettings>
</Controller>
</C-JDBC-CONTROLLER>
You can specify at startup a different file than config/controller/controller.xml. This is useful if you have to startup many identical controllers from the network. You can then use the command controller.sh -f filename on Unix machines or controller.bat -f filename on windows.
For more information you can refer to the controller-configuration.xml example in the example directory of c-jdbc.
Next section describes how to write a controller configuration file.
The controller is entirely configurable via an xml file, by default it is controller.xml located in the config/controller of the C-JDBC installation. This section details how to write such a file.
The root element of the controller configuration is defined as follows
<!ELEMENT Controller (Internationalization?, Report?, JmxSettings?,
VirtualDatabase*, SecuritySettings?)>
<!ATTLIST Controller
port CDATA "25322"
ipAddress CDATA "127.0.0.1"
backlogSize CDATA "10"
>
All sub-elements of Controller are defined in the next sections. Here is a brief overview of each of them:
Internationalization: defines the language setting for C-JDBC console and error messages.
Report: if this option is enabled, C-JDBC can automatically generate a report on fatal errors or shutdown. If you experience any problem with C-JDBC, you can directly send the report on the mailing list to get a quick diagnostic of what happened.
JmxSettings: JMX is the technology used for management and monitoring in C-JDBC. These functionalities can be accessed through HTTP with an internet browser or through the RMI connector used by the C-JDBC console.
VirtualDatabase: Defines a virtual database to load automatically at controller startup given a reference to its configuration file.
SecuritySettings: Allows to filter accesses to a controller based on access lists.
The attributes of a Controller element are defined as follows:
port: the port number on which clients (C-JDBC drivers) will connect. The default port number is 25322.
| Note |
|---|---|
A port number below 1024 will require running the controller with privileged rights (root user under Unix). | |
ipAddress: This can be defined to bind a specific IP address in case of a host with multiple IP addresses. This can be ignored if there is only one IP address available and will be replaced by 127.0.0.1.
backlogSize: the server socket backlog size (number of connections that can wait in the accept queue before the system returns "connection refused" to the client). Default is 10. Tune this value according to your operating system, but the default value should be fine for most settings.
If your machine has multiple network adapters, you can for the C-JDBC Controller to bind a specific IP address like this:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<!DOCTYPE C-JDBC-CONTROLLER PUBLIC "-//ObjectWeb//DTD C-JDBC-CONTROLLER 2.0.2//EN" "http://c-jdbc.objectweb.org/dtds/c-jdbc-controller-2.0.2.dtd">
<C-JDBC-CONTROLLER>
<Controller port="25322" ipAddress="192.168.0.1">
<JmxSettings enabled="false"/>
</Controller>
</C-JDBC-CONTROLLER>
You can use this element to override the default locale retrieved by java. English is the only language looked at at the moment.
<!ELEMENT Internationalization EMPTY>
<!ATTLIST Internationalization language (en|fr|it|jp) "en">
A report can be define in case you want to get a trace of what happened during the execution of the controller. If this element is included in the controller.xml report is enabled and will output a report, under certain conditions, in a file named c-jdbc.report.
<!ELEMENT Report EMPTY>
<!ATTLIST Report
hideSensitiveData (true|false) "true"
generateOnShutdown (true|false) "true"
generateOnFatal (true|false) "true"
enableFileLogging (true|false) "true"
reportLocation CDATA #IMPLIED
>
hideSensitiveData: will replace passwords with '*****'.
generateOnShutdown: tells the controller to generate a report when it has received a shutdown command.
generateOnFatal: tells the controller to generate a report when it cannot recover from an error.
enableFileLogging: logs all the console output into a file and include this file into the report.
reportLocation: specify the path where to create the report, default is CJDBC_HOME/log directory.
JMX is used to remotely administrate the controller. You can use the bundled C-JDBC console or use your own code to access JMX MBeans via the protocol adaptor. C-JDBC proposes both the RMI and HTTP adaptors of the MX4J JMX server. You can override the default port numbers for each adaptor if they conflict with another application that is already using them (i.e. another C-JDBC controller on the same machine).
<!ELEMENT JmxSettings (HttpJmxAdaptor?, RmiJmxAdaptor?)>
<!ELEMENT HttpJmxAdaptor EMPTY>
<!ATTLIST HttpJmxAdaptor
port CDATA "8090"
>
<!ELEMENT RmiJmxAdaptor (SSL?)>
<!ATTLIST RmiJmxAdaptor
port CDATA "1090"
username CDATA #IMPLIED
password CDATA #IMPLIED
>
<!ELEMENT SSL EMPTY>
<!ATTLIST SSL
keyStore CDATA #REQUIRED
keyStorePassword CDATA #REQUIRED
keyStoreKeyPassword CDATA #IMPLIED
isClientAuthNeeded (true|false) "false"
trustStore CDATA #IMPLIED
trustStorePassword CDATA #IMPLIED
>
Configure ssl for encryption and/or authentication.
keyStore: The file where the keys are stored
keyStorePassword: the password to the keyStore
keyStoreKeyPassword: the password to the key, if none is specified the same password as for the store is used
isClientAuthNeeded: if set to false ssl is used for encryption, the server is only accepting trusted clients (the client certificate has to be in the trusted store)
trustStore: the file where the trusted certificates are stored, if none is specified the same store as for the key is used
trustStorePassword: the password to the trustStore, if none is specified the same password as for the keyStore is used
You have to enable the RMI adaptor if you want to use the C-JDBC console to administrate the controller remotely. To enable the RMI JMX adaptor, use this setting:
<JmxSettings>
<RmiJmxAdaptor/>
</JmxSettings>
This element specifies virtual databases to load at controller startup.
<!ELEMENT VirtualDatabase EMPTY>
<!ATTLIST VirtualDatabase
configFile CDATA #REQUIRED
virtualDatabaseName CDATA #REQUIRED
autoEnableBackends (true | false | force) "true"
checkpointName CDATA ""
>
configFile: The path to the virtual database configuration file. See Section 11, “Virtual database configuration” to learn how to write a virtual database configuration file.
virtualDatabaseName: The name of the virtual database since the configuration file can contain multiple virtual database definitions.
autoEnableBackends: set to true by default to reenable backends from their last known state as stored during last shutdown. If backends where not properly shutdown, nothing will happen. You can specify false to let the backends in disabled state at startup. The force option should only be used if you know exactly what you are doing and override backend status by providing a new checkpoint. Warning! Use this setting carefully as it might break your database consistency if you do not provide a valid checkpoint.Force is considered the same as true if no recovery log has been defined.
checkpointName: the checkpoint name to use with the recovery log to enable backend from a known coherent state. If the checkpoint is omitted, the last known checkpoint is used.
Example:
<VirtualDatabase configFile="/databases/MySQLDb.xml" virtualDatabaseName="rubis" autoEnableBackends="true"/>
This will enable a virtual database named rubis taken from a configuration file named /databases/MySQLDb.xml and will enable all backends of the database from the last known checkpoint.
Security settings define the policy to adopt for some functionalities that may compromise the security of the controller. These settings depends on your environment and can be relaxed if you are running in a secure network. The less security settings you have, the faster the controller will run. A SecuritySettings element is defined as follows:
<!ELEMENT SecuritySettings (Jar?, Shutdown?, Accept?, Block?)>
<!ATTLIST SecuritySettings
defaultConnect (true|false) "true"
>
defaultConnect: is used to allow (true) or refuse (false) connections to the controller. This default setting can be then be tuned with access lists defined in Accept and Block elements (see below).
Additional database drivers can be uploaded dynamically to the controller. As the controller has no way to check if this is a real JDBC driver or some malicious code hidden a JDBC driver interface, you have to be very careful if you enable this option and anybody can connect from anywhere to your controller.
<!ELEMENT Jar EMPTY>
<!ATTLIST Jar
allowAdditionalDriver (true|false) "true"
>
The Shutdown element defines how the controller can be terminated - in order to shutdown the controller properly, we have to use the console. Specify if the controller should consider shutdown command received by one or the other, and if this command can only be received from localhost or not. A default configuration would be:
<Shutdown>
<Client allow="true" onlyLocalhost="true"/>
<Console allow="true" onlyLocalhost="true"/>
</Shutdown>
This prevents unwanted and unauthorized shutdown calls from remote hosts. Only somebody logged locally on the machine can request a shutdown of the controller. Here is the full description for details:
<!ELEMENT Shutdown (Client?,Console?)>
<!ELEMENT Client EMPTY>
<!ATTLIST Client
allow (true|false) "true"
onlyLocalhost (true|false) "true"
>
<!ELEMENT Console EMPTY>
<!ATTLIST Console
allow (true|false) "true"
onlyLocalhost (true|false) "true"
>
You can control who can connect to the controller by setting access lists based on IP addresses to accept or block. defaultConnect is set in SecuritySettings defined above. Default is to accept all connections if no security manager is enabled.
<!ELEMENT Accept (Hostname|IpAddress|IpRange)*>
<!ELEMENT Block (Hostname|IpAddress|IpRange)*>
<!ELEMENT Hostname EMPTY>
<!ATTLIST Hostname
value CDATA #REQUIRED
>
IpAddress value is an IPv4 address (ex:192.168.1.12):
<!ELEMENT IpAddress EMPTY>
<!ATTLIST IpAddress
value CDATA #REQUIRED
>
IpRange value is based on IPv4 addresses and has the following form: 192.168.1.*.
<!ELEMENT IpRange EMPTY>
<!ATTLIST IpRange
value CDATA #REQUIRED
>
Here is a full security configuration example:
<SecuritySettings defaultConnect="false">
<Jar allowAdditionalDriver="true"/>
<Shutdown>
<Client allow="true" onlyLocalhost="true"/>
<Console allow="false"/>
</Shutdown>
<Accept>
<IpRange value="192.168.*.*"/>
</Accept>
</SecuritySettings>
This setting accepts driver connections only from machines having an IP address starting with 192.168, allows loading of additional drivers via the console, refuses shutdown from the console, but allows it from the local machine.
C-JDBC uses the Log4j logging framework. The log4j.properties configuration file is located in the /c-jdbc/config directory of your installation. Here is a brief description of the loggers available in the configuration file:
log4j.logger.org.objectweb.cjdbc.core.controller: Controller related activities mainly for bootstrap and virtual database adding/removal operations.
log4j.logger.org.objectweb.cjdbc.controller.xml.Handler: XML configuration file parsing and handling.
log4j.logger.org.objectweb.cjdbc.controller.VirtualDatabase: Virtual database related operations. A specific log4j.logger.org.objectweb.cjdbc.controller.VirtualDatabase.virtualDatabaseName logger is automatically created for each virtual database. This allows to tune different logging levels for each virtual database.
log4j.logger.org.objectweb.cjdbc.controller.VirtualDatabase.request: Log the incoming requests and transactions in files that can be replayed by the Request Player tool provided with C-JDBC.
log4j.logger.org.objectweb.cjdbc.controller.distributedvirtualdatabase.request : Log distributed request execution when using horizontal scalability (a.k.a. controller replication).
log4j.logger.org.objectweb.cjdbc.controller.backup : Log backup manager and backuper related activities from dump/restore operations.
log4j.logger.org.objectweb.cjdbc.controller.VirtualDatabaseServerThread: The server thread accepts client connections and manages the worker threads.
log4j.logger.org.objectweb.cjdbc.controller.VirtualDatabaseWorkerThread: Each worker thread handle a session with a client C-JDBC driver.
log4j.logger.org.objectweb.cjdbc.controller.RequestManager: Log the request flows between the different Request Manager components (scheduler, cache, load balancer, recovery log).
log4j.logger.org.objectweb.cjdbc.controller.scheduler: Log the request ordering and synchronization performed by the scheduler.
log4j.logger.org.objectweb.cjdbc.controller.cache: SQL Query cache related activities.
log4j.logger.org.objectweb.cjdbc.controller.loadbalancer: Log how requests are balanced on the backends.
log4j.logger.org.objectweb.cjdbc.controller.connection: Connection pooling related information.
log4j.logger.org.objectweb.cjdbc.controller.recoverylog: C-JDBC Recovery Log information.
log4j.logger.org.objectweb.cjdbc.controller.console.jmx: JMX management system logging.
log4j.logger.org.objectweb.tribe.channels: Tribe low level group communication channel.
log4j.logger.org.objectweb.tribe.gms: Tribe Group Membership Service (GMS).
log4j.logger.org.objectweb.tribe.discovery: Tribe Discovery Service (used by GMS).
og4j.logger.org.objectweb.tribe.blocks.multicastadapter: Tribe Multicast Dispatcher building block for application level message handling.
When you want to add a database to your cluster, you do not want to stop the system, replicate the current database state to the new database (that may take a long while) and then restart the system. The Recovery Log helps you in the process of dynamically adding a new backend (or recovering a previously failed backend) without stopping the system.
The Recovery Log records the write operations and transactions that are performed by the C-JDBC controller between checkpoints. A checkpoint is just a logical index in the log that reflect the recovery log state at a given time. As of C-JDBC 2.0, checkpoints are automatically managed by the controller and are generated when needed on behalf of the administrator when a backend is disabled or enter a backup phase. When re-enabling the backend, the Recovery Log replays all write queries and transactions that the backend missed during the time it was offline and it comes back to the enabled state once it is synchronized with the other nodes.
| Note |
|---|---|
Since version 2.0, the backup infrastructure has completely changed and is based on Backupers. We provide a generic Backuper based on Enhydra Octopus to copy, backup and restore content of backends through JDBC. Even if Octopus is supposed to handle most common databases, it might fail for some specific databases or data types. In that case, we strongly recommend to use or implement a database specific Backuper. | |
Your Web site is running with a single database and you want to use C-JDBC with three nodes using full replication (RAIDb-1). You have two new backends ready to be installed. You can start the C-JDBC console and connect to the controller. Start the administration module by connecting to the virtual database. Type: backup <backend name> <dump name> <backuper name> <path to backup directory>. If you want to use Octopus you will use a command line like backup node1 dump1 Octopus /var/backups. During the backup, the update requests are logged in the recovery log, so no update is lost. If the backend was in the enabled state when backup was initiated, it will automatically replay the recovery log to resynchronize itself and return to the enabled state.
To restore the dump on another backend, just type restore <newbackend> <dumpname> and the appropriate backuper (Octopus in our previous example) will be used to restore the dump. After restoring the dump, you can enable the backend at any time so that the recovery log replays all the missing requests since the dump was taken.
Here is the set of commands to use in the C-JDBC console if node1 is your existing backend and you want to dynamically add node2 and node3:
backup node1 initial_dump Octopus /var/backups
restore node2 initial_dump
restore node3 initial_dump
enable node2
enable node3
| Note |
|---|---|
Note that these steps can be automated by scriptin the console. | |
If a node crashes, use the administration console to restore the dump on the node using the restore command. Once the dump is restored, re-enable the backend from the stored checkpoint and the Recovery Log will automatically replay all the write queries to rebuild a consistent database state on the node.
To prevent the recovery log from being too large, you can periodically perform backup operations. This will also lower the recovery time since the part of the log to replay will be smaller. You can delete older dumps and logs if you do not need them anymore.
A checkpoint is a reference used by the recovery log to replay missing requests. If a backend is disabled from the console for maintenance, the controller will automatically create a checkpoint (prior to v2.0, the checkpoint name had to be provided manually through the console). Once the backend is enabled again, the controller retrieves its last known checkpoint from the recovery log and replays all the requests that the disabled backend missed since it was disabled. A checkpoint is nothing more than a reference in time.
As the C-JDBC recovery log can be stored in a database providing a JDBC driver, it is possible to make the recovery log fault tolerant by redirecting it to a C-JDBC controller (even self) that will distribute and replicate the log content on several backends.
The JDBC Recovery Log configuration is detailed in Section 11.6.5, “Recovery Log”.
To prevent the C-JDBC controller from being a single point of failure, C-JDBC provides controller replication also called horizontal scalability. A virtual database can be replicated in several controllers that can be added dynamically at runtime. Controllers use the JGroups group communication middleware to synchronize updates in a distributed way. The JGroups stack configuration is found in config/jgroups.xml and should not be altered unless you specifically know what you are doing. Keep in mind that total order reliable multicast is needed to ensure proper synchonization of the controllers. More information about JGroups can be found on the JGroups web site. Note that JGroups requires proper network settings, here are a few guidelines:
a default route must be defined (check with /sbin/route under Linux) for the network adapter which is bound by JGroups (usually eth0). If such route does not exist, either the group communication initialization will block or controllers will not be able to see each other even on the local host. If you don't have any default entry in your routing table you can use a command like '/sbin/route add default eth0' to define this default route.
issues have been reported with DHCP that can either block (under Windows) or just fail to properly set a default route and leads to the issue reported above. We strongly discourage the use of DHCP, you should use fixed IP addresses instead.
name resolution should be properly set so that the IP address/machine name matching works both ways. Often improper /etc/hosts or DNS configuration leads to group communication initialization problems. In particular, under Linux, the IP address associated to the name returned by the 'hostname' command must not resolve to 127.0.0.1 else controllers will not see each other.
In order for a virtual database to be replicated, you must define a Distribution element in the virtual database configuration file (see Section 11.2.1, “Distribution”). There are several constraints for different controllers to replicate a virtual database:
give the list of all controllers that you plan to use for replication of your virtual database in the C-JDBC driver URL. Even if all controllers are not online at all times, the driver will automatically detect the alive controllers: jdbc:cjdbc://node1,node2,node3,node4/myDB
the virtual database must have the same name and use the same groupName (in the Distribution element).
each controller must have its own set of backends and no backends should be shared between controllers (C-JDBC checks the database URLs, having different backend names is not sufficient).
each controller must have its own recovery log, recovery logs cannot be shared. It is possible for a controller not to have a recovery log but this controller will have no recovery capabilities.
the authentication managers must support the same logins.
schedulers and load balancers must implement the same RAIDb configuration.
database schemas (if defined) must be compatible according to the RAIDb level you are using.
| Note |
|---|---|
As backends cannot be shared between controllers, it is not possible to use a SingleDB load balancer with controller replication. If each controller only has a single database backend attached to it, then you must use a RAIDb-1 configuration since in fact you have 2 replicated backends in the cluster. | |
Several configuration file examples are available in the doc/examples/HorizontalScalability directory of your C-JDBC distribution.
| Note |
|---|---|
You can find more information in the document titled "C-JDBC Horizontal Scalability - A controller replication user guide" available from the C-JDBC web site. | |
The C-JDBC controller in its 2.0.2 release has the following limitations:
GRANT/REVOKE commands will be sent to the database engines but this will not add or remove users from the virtual database authentication manager.
network partition/reconciliation is not supported,
distributed joins are not supported which means that you must ensure that every query can be executed by at least a single backend,
RAIDb-1ec and RAIDb-2ec levels are not supported,
| |  | |
| 5. Configuring C-JDBC with 3rd party software |  | 7. Administration console |