| C-JDBC User's Guide | ||
|---|---|---|
 | ||
| C-JDBC User's Guide | ||
|---|---|---|
| | ||
Version 2.0.2
Copyright © 2002, 2003, 2004, 2005 French National Institute For Research In Computer Science And Control (INRIA), Emic Networks
Java, and all Java-based trademarks are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries.
Table of Contents
C-JDBC is a database cluster middleware that allows any Java™ application (standalone application, servlet or EJB™ container, ...) to transparently access a cluster of databases through JDBC™. You do not have to modify client applications, application servers or database server software. You just have to ensure that all database accesses are performed through C-JDBC.
C-JDBC is a free, open source project of the ObjectWeb Consortium. It is licensed under the GNU Lesser General Public License (LGPL).
In order to use C-JDBC, you will need:
a client application that accesses a database through JDBC,
a JDK™ 1.3 (or greater) compliant Java Virtual Machine™ (JVM)[1],
a database with a JDBC driver (type 1, 2, 3 or 4) or an ODBC driver used with the JDBC-ODBC bridge.
a network supporting TCP/IP communications between your cluster nodes.
![[Note]](../../images/note.gif) | Note |
|---|---|
If your client application uses ODBC, it is possible to use an ODBC-JDBC bridge such as the unixODBC provided by Easysoft. | |
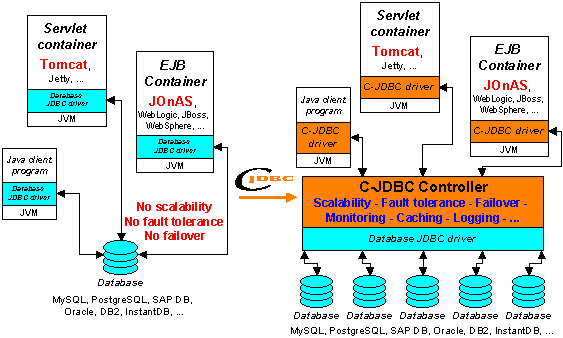
You have a Java application or a Java-based application server that accesses one or several databases. The database tier becomes the bottleneck of your application or it is a single point of failure or both. C-JDBC can help you resolve these problems by providing:
performance scalability by adding database nodes and balacing the load among these nodes.
high availability of the database tier, i.e. C-JDBC tolerates database crashes and offers transparent failover using database replication techniques.
improved performance with fine grain query caching and transparent connection pooling.
SQL traffic logging for performance monitoring and analysis.
support for clusters of heterogenous database engines.
C-JDBC provides a flexible architecture that allows you to achieve scalability, high availability and failover with your database tier. C-JDBC implements the concept of RAIDb: Redundant Array of Inexpensive Databases (see Section 10, “RAIDb Basics”). The database is distributed and replicated among several nodes and C-JDBC load balances the queries between these nodes.
C-JDBC provides a generic JDBC driver to be used by the clients (see Section 4, “C-JDBC Driver”). This driver forwards the SQL requests to the C-JDBC controller (see Section 6, “C-JDBC controller”) that balances them on a cluster of databases (reads are load balanced and writes are broadcasted). C-JDBC can be used with any RDBMS (Relational DataBase Management System) providing a JDBC driver, that is to say almost all existing open source and commercial databases. Figure 1, “C-JDBC principle” gives an overview of the C-JDBC principle.
C-JDBC allows to build any cluster configuration including mixing database engines from different vendors. The main features provided by C-JDBC are performance scalability, fault tolerance and high availability. Additional features such as monitoring, logging, SQL requests caching are provided as well.
The architecture is widely open to allow anyone to plug custom requests schedulers, load balancers, connection managers, caching policies, ...
From a software point of view, C-JDBC is an open-source software licensed under LGPL which means that it is free of charge for any usage (personal or commercial). If you are using commercial RDBMS (such as Oracle, DB2, ...), you will have to buy extra licenses for the nodes where you install replicas of the database. But you can possibly use open-source databases to host replicas of your main database.
You need to buy extra machines if you want more performance and more fault tolerance. C-JDBC has been designed to work with standard off-the-shelf workstations because it primarily targets low cost open-source solutions but it can work as well with large SMP machines. A standard Ethernet network is sufficient to achieve good performance.
You do not have to change anything to your application or your database.
You only have to update the JDBC driver configuration used by your application (usually it is just a configuration file update) and to setup a C-JDBC configuration file (see Section 11, “Virtual database configuration”).
| | ||
| 2. Getting the Sofware |